All large language models (LLMs) have two fundamental limitations: LLMs lack knowledge of events that occurred after their training date, a phenomenon known as the knowledge cutoff, and they tend to generate incorrect or fabricated information, often referred to as hallucination. Overcoming these limitations and improving the reliability of LLM output is crucial. This blog post will explore strategies for addressing these challenges.
Knowledge Structures in LLMs: Parametric Vs. Non-parametric
Large Language Models (LLMs) can carry two distinct types of knowledge. The knowledge embedded within the model itself, residing in its weights and biases, is called parametric knowledge. In contrast, non-parametric knowledge is external to the LLM’s parameters and can be added through embedded text. This type of non-parametric knowledge can originate from a variety of sources, including documents such as text files, PDFs, and PPTs, as well as websites.
Grounding of an LLM
Grounding is the process of enriching the LLM with domain-specific information, enabling it to understand and produce responses that are not only accurate but also contextually relevant to specific domains. This can be achieved by augmenting the model’s parametric knowledge or adding non-parametric knowledge.
Methods That Augment Parametric Knowledge of LLMs
Methods that augment parametric knowledge of LLMs can be grouped into two categories: fine-tuning and knowledge distillation.
Fine-tuning involves modifying the model’s weights or parameters to fit a specific task, which is achieved through techniques such as parameter-efficient fine-tuning (PEFT). PEFT updates a subset of the model’s weights with new data, allowing it to adapt to new tasks while preserving most of its pre-trained knowledge. Another technique within this group is low-rank adaptation (LORA), which factorizes the model’s weights into low-rank components that can be easily updated.
Knowledge distillation, on the other hand, transfers knowledge from a pre-trained teacher model to a smaller student model by training the student on the outputs of the teacher. This process enables the student model to learn from the teacher’s existing knowledge and adapt to new tasks with minimal retraining.
Methods That Add Non-parametric Knowledge to LLMs
The dominant method in this category is called Retrieval-Augmented Generation (RAG). A RAG pipeline functions by retrieving relevant information from a data source, which could include files from local or remote file systems, databases, or data obtained through API calls. This retrieved information serves as context for the subsequent generation of the final response. Basic RAG pipelines typically comprise three key elements: Data Ingestion, Retrieval, and Generation.
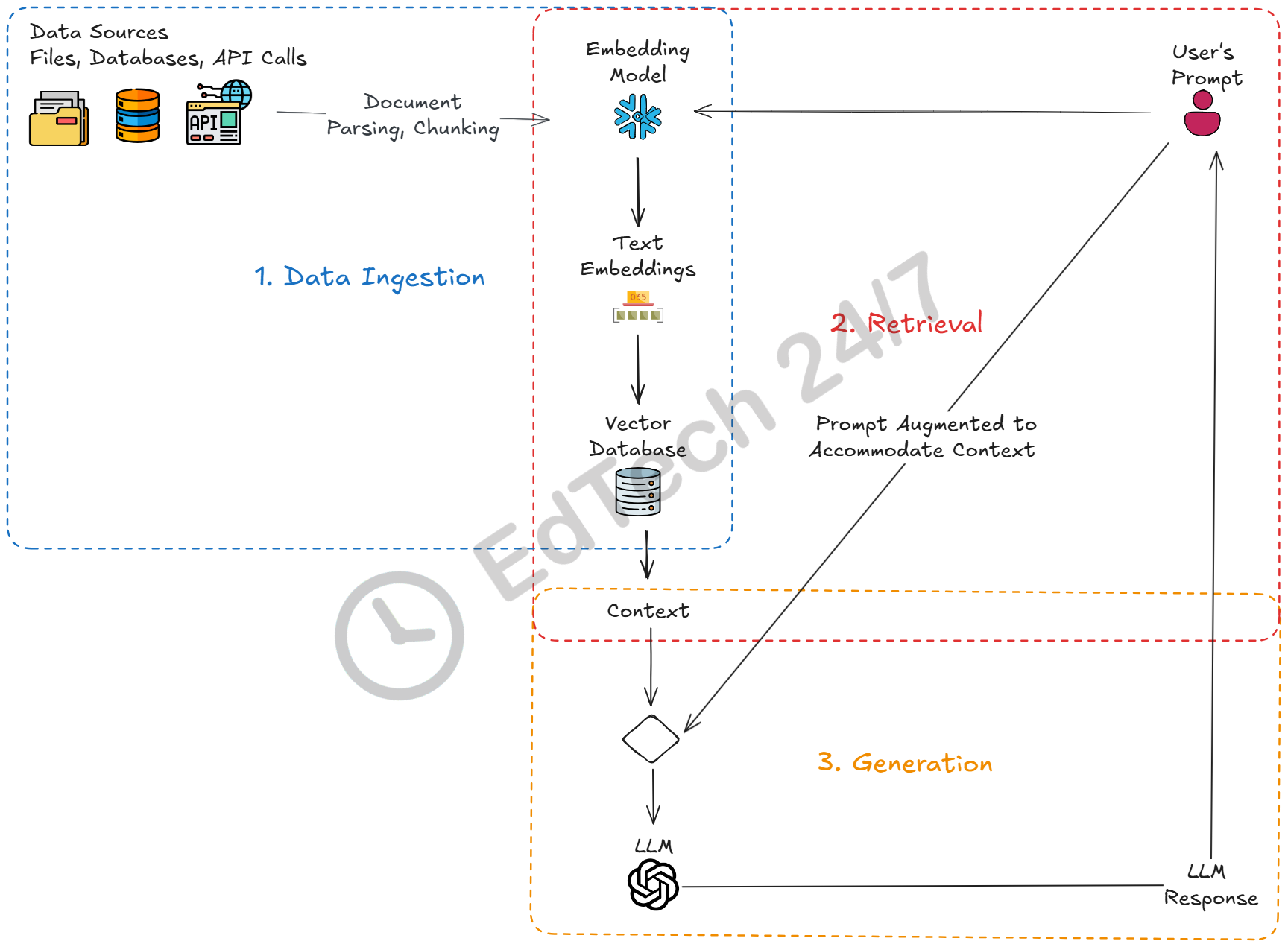
During the data ingestion phase of a RAG pipeline, several crucial steps occur to prepare the data for efficient retrieval and generation. First, a document parser extracts raw textual data from the document, including text, headings, tables, and other content. Next, the extracted text is chunked into smaller sections, enabling more precise control over data processing. Each chunk is then converted into vector representations called embeddings that capture the essence of the text’s meaning and structure. The smaller models that convert text chunks to vectors are called embedding models. Some popular embedding models include Nomic-Embed and Snowflake Arctic. Finally, these embedded chunks are saved in a vector store, a database designed for efficient retrieval and querying of large amounts of vectorized data—typically referred to as a knowledge base in most RAG systems.
The Retrieval Module searches the knowledge base for information relevant to the user’s query. It does this by converting the user’s query into vectors (embeddings) and using them to quickly find the most relevant information in the vector store. These vectors are generated by the same embedding model used during data ingestion.
Once relevant information is retrieved from the knowledge base, it’s fed into the Generation Module. This module merges the context obtained from the vector store with the user’s original prompt to generate a final response incorporating both inputs. The user’s original prompt is augmented to include the retrieved context. For example, the new prompt might read:
Answer the user’s {question} based on the {context}, where “{question}” refers to the user’s original prompt and “{context}” refers to the information retrieved from the vector store.
The generation model, essentially a large language model (LLM), processes both the augmented prompt and context to generate coherent and accurate text. It achieves this by predicting the next word or token in a sequence based on the provided input.
Final Thoughts
Fixing the major flaws in large language models (LLMs) - like outdated knowledge and made-up facts - requires a multi-faceted approach. Fine-tuning can be helpful for teaching new skills, but it’s not practical or affordable for keeping general knowledge up-to-date. A more efficient solution is Retrieval-Augmented Generation (RAG), which lets LLMs tap into massive external knowledge bases and learn from them. By using RAG to focus LLMs on specific areas of expertise, they become more accurate, better at understanding context, and more reliable.


 Dr. Lochana C. Menikarachchi
Dr. Lochana C. Menikarachchi
