Welcome! You are about to explore the fascinating world of large language models (LLMs). In this blog post, we will take a closer look at what LLMs are and how they work their magic. We’ll also examine various techniques for crafting effective prompts and fine-tuning model settings to get the best possible results.
No Time? Listen to the Audio Deep Dive!
Contents
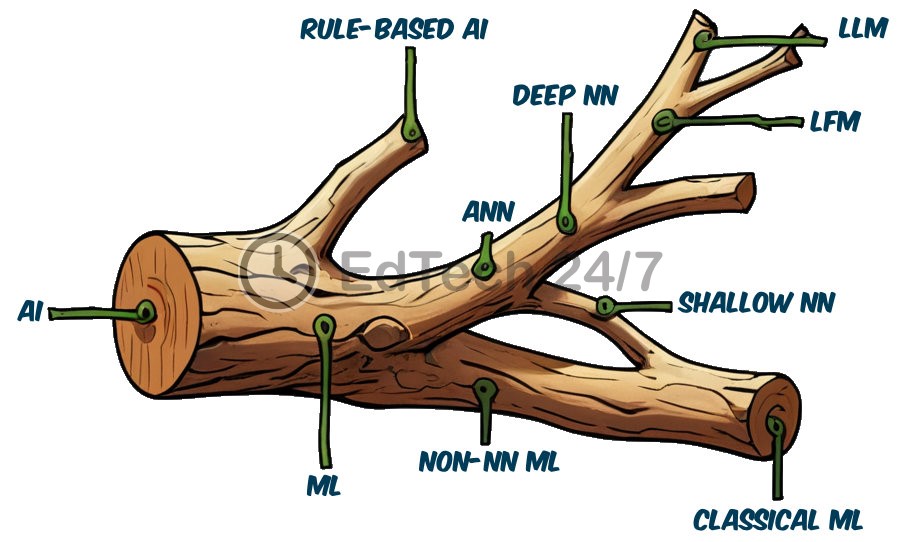
Where do LLMs Stand in the AI Spectrum?
People often confuse large language models (LLMs) with artificial intelligence (AI) and generative AI (GenAI), but they have different meanings. Let’s take a closer look at these terms to understand where LLMs fit in the overall artificial intelligence landscape.
Artificial Intelligence (AI): Artificial intelligence refers to systems and machines that mimic human intelligence, enabling them to perform tasks that typically require cognitive abilities such as problem-solving, decision-making, learning, and perception.
We can broadly divide AI into two categories: machine learning (ML) and rule-based AI.
Machine Learning (ML): Machine learning is a subset of artificial intelligence where systems are explicitly designed to learn from data rather than being programmed with explicit rules. These systems use algorithms to identify patterns in the data and make predictions or decisions based on that information. ML models can improve their performance over time as they receive more data, enabling them to adapt to new situations and tasks.
Rule-Based AI: Rule-based artificial intelligence systems mimic human intelligence by using pre-defined rules and algorithms, rather than learning from data. They rely on explicit programming to guide their behavior, ensuring predictable output in well-structured environments.
Machine learning (ML) can be further divided into two categories: non-neural network based ML and artificial neural networks (ANN).
Non-NN ML: Non-neural network based ML, also known as classical machine learning, utilize statistical learning techniques for tasks like classification, regression, and clustering. Algorithms include logistic regression, decision trees, random forests, support vector machines (SVMs) and k-nearest neighbors (k-NN), among others. These methods offer interpretability but may struggle with complex data sets. Another downside to classical machine learning is that it requires manual tasks such as algorithm selection, feature engineering, parameter tuning and model optimization.
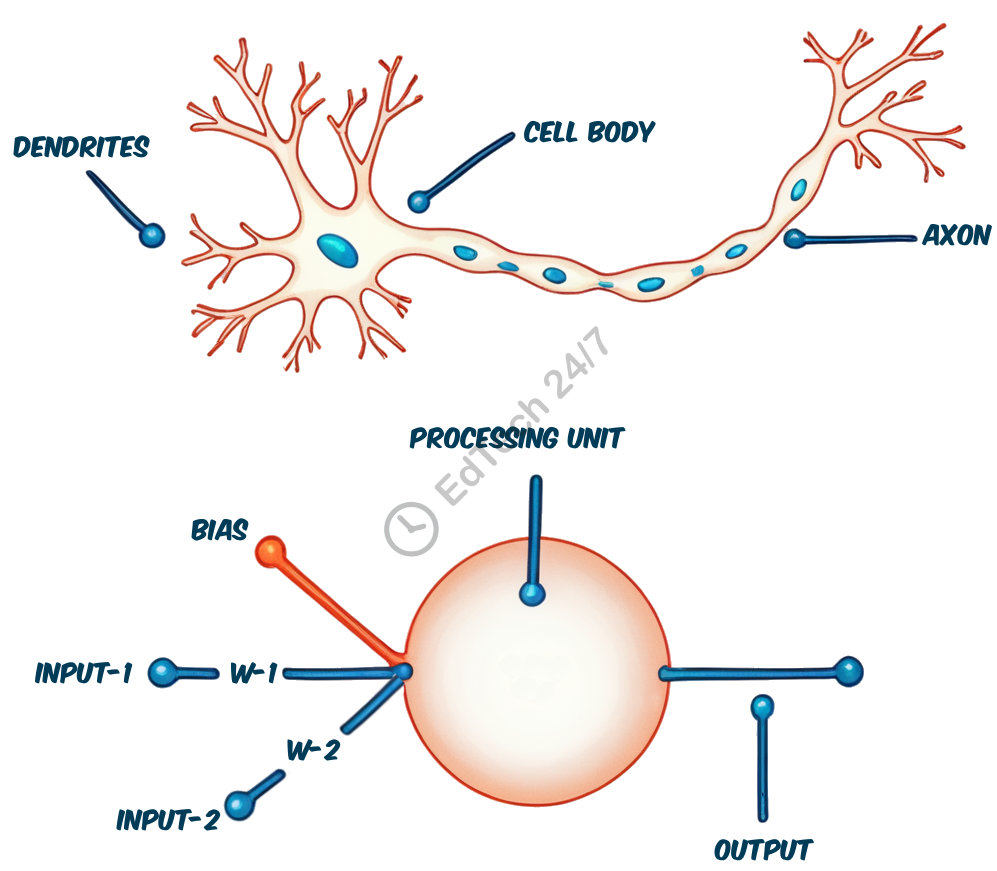
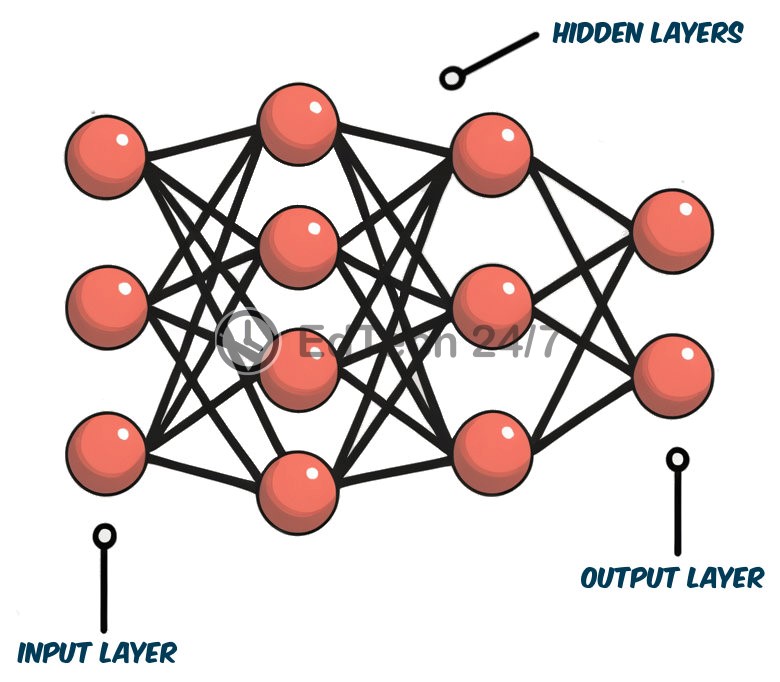
ANN: Artificial neural networks (ANNs) draw inspiration from the structure and function of biological neurons, which collect information through dendrites, process it within their cell body, and transmit signals to other neurons via axons. Similarly, artificial neurons receive data through inputs, learn patterns from this input using a core processing unit, and send signals to other artificial neurons through outputs. Each input is associated with a weight term that indicates its relative importance, while the neuron’s bias determines how easily it fires. These weights and bias are the neuron’s parameters. In an ANN, individual neurons are organized into multiple layers, typically consisting of an input layer, an output layer, and one or more hidden layers situated between them.
Shallow NN: A shallow neural network is a type of artificial neural network (ANN) that consists of one or two hidden layers situated between the input and output layers. Similar to classical machine learning methods, shallow neural networks require manual tuning to achieve optimal performance (see the merged branches in the figure).
Deep NN: Deep neural networks have a large number of hidden layers between the input and output layers, which allows them to automatically capture complex hierarchical features in data with minimal manual parameter tuning required. This architecture enables deep learning models to learn abstract representations of data, leading to state-of-the-art performance on various tasks such as image classification, speech recognition, and natural language processing.
LFM: Large Foundational Models (LFMs) are large-scale neural networks trained on a vast volume of diverse data, including text, images, audio, and video. This training enables them to acquire a broad understanding of the world, making them versatile foundation models for various AI applications.
LLM: Large language models (LLMs) are a type of LFM, specifically trained on vast amounts of textual data to acquire a profound understanding of human communication, enabling applications such as language generation, translation, and analysis.
Generative AI (GenAI): Generative AI (GenAI) creates new content, ideas, or data based on user input. This includes language models that generate human-like text responses, translate languages accurately, and even create original stories or articles. By learning patterns in existing data, generative AI models can also produce realistic images, music, speech, and videos, pushing the boundaries of what is possible with artificial intelligence.
What are LLMs?
Large Language Models (LLMs) are sophisticated text generators that produce contextually relevant output by applying Bayes’ theorem with learned probabilities. When you input some text to an LLM, it uses its understanding of language statistics and relationships to make predictions about what comes next in a coherent and meaningful way, effectively completing or continuing the text. This process relies on patterns extracted from the model’s vast training data, enabling it to generate human-like text that captures nuances and complexities of language.
Tokenization and Text Embedding
Since LLMs (Large Language Models) are based on artificial neural networks (ANNs), they can only process numerical data. To accommodate textual inputs, two steps are necessary: tokenization and text embeddings. Tokenization involves breaking down input text into smaller chunks, such as words or sentences. Text embeddings represent these words with numerical vectors that convey their meaning and relationship to other words, allowing the model to understand the context and nuances of language.
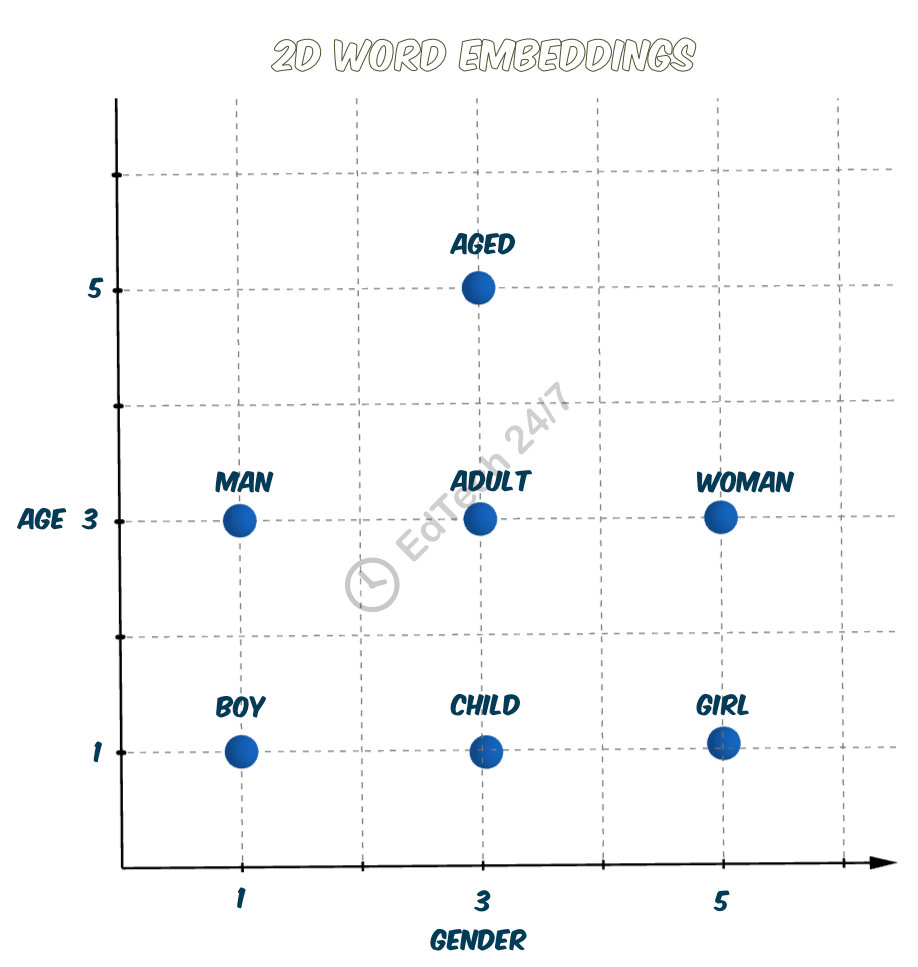
Let’s take a closer look at how we can embed words related to gender and age using 2D numerical vectors. As illustrated in the figure, similar age categories and genders tend to cluster together, demonstrating a clear pattern of semantic relationships.
Text
Text Embedding
boy
[1,1]
man
[1,3]
child
[3,1]
adult
[3,3]
girl
[5,1]
woman
[5,3]
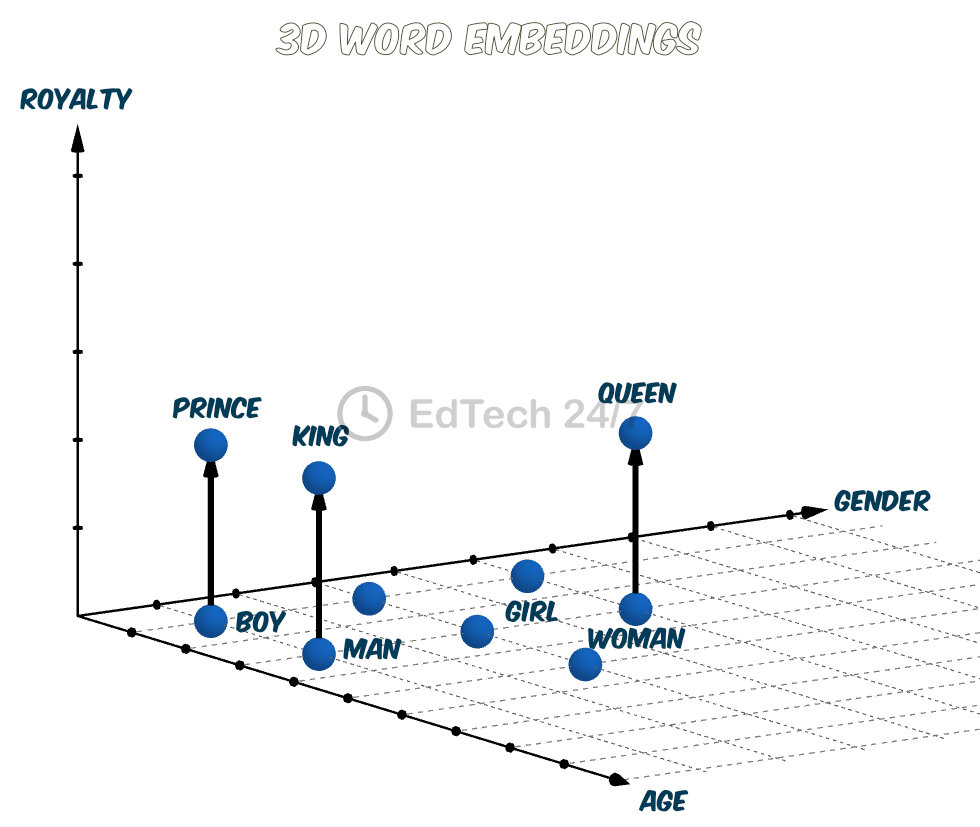
Let’s enhance our word embeddings by adding an additional dimension to capture how words like prince, king, and queen relate to the rest of the dataset. This new dimension, which we’ll call royalty, allows these terms to cluster together in a meaningful way. Take a look at the numerical vectors that result from this addition - they now have three dimensions: two for capturing word meanings within the existing space, and one for representing their membership in the royalty category.
Text
Text Embedding
boy
[1,1,0]
man
[1,3,0]
child
[3,1,0]
adult
[3,3,0]
girl
[5,1,0]
woman
[5,3,0]
prince
[1,1,2]
king
[1,3,2]
queen
[5,3,2]
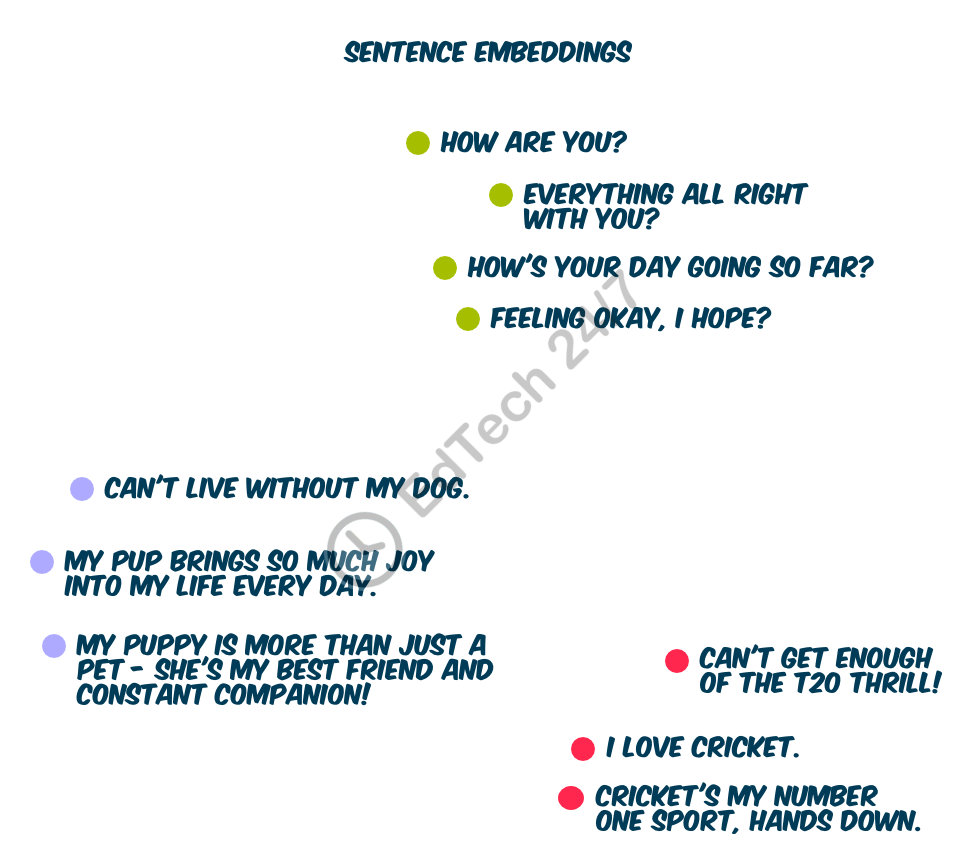
Just like individual words, entire sentences can be embedded, resulting in a single vector that captures their semantic meaning and context. This embedding enables meaningful relationships between sentences to emerge, allowing for the identification of clusters with similar meaning. For instance, consider the following illustration, which demonstrates how sentences with analogous meanings are grouped together.
To map out semantic relationships between sentences, we clearly need more than three dimensions. In real large language models (LLMs), the number of dimensions used can range from several hundreds to several thousand.
Prompts and Prompt Engineering Writing Techniques
The effectiveness of a large language model (LLM) largely depends on the quality of its input, commonly referred to as the prompt. A well-crafted prompt not only guides the model’s behavior but also encourages high-quality and relevant outputs, enabling it to perform optimally.
To produce good results with large language models (LLMs), consider employing various prompt writing techniques. One effective approach is to provide clear instructions that outline the objective of the task, the expected format of the output, any constraints or limitations, and relevant context or background information. For example: “Write a 250-word summary of the main events in Shakespeare’s Hamlet.”
Splitting a large task into smaller subtasks is another way to optimize an LLM’s output, allowing us to guide its attention and focus towards specific aspects of the problem. This approach becomes particularly effective when asking the LLM to provide step-by-step guidance on each subtask. For instance: “Write a plan to prepare for an 8-hour road trip. Please break down your response into three sections: planning, preparation, and execution.”
Another technique involves asking the LLM to justify its responses, which encourages it to provide well-reasoned and logical outputs. This can be achieved by adding phrases such as “explain why” or “justify your answer.” For example: “What are three possible reasons why Romeo and Juliet’s families hate each other?”
Generating multiple outputs is another powerful technique that allows the model to explore different possibilities and perspectives, making it more robust and versatile. By asking the LLM to provide several options for an answer, we can give it the freedom to experiment with different ideas and approaches. For instance: “What are three possible solutions to world hunger? Please generate at least five responses and pick the best three.”
To reduce the influence of recency bias, which refers to the tendency for LLMs (and humans) to give more weight to recent information over older or established knowledge, it’s essential to repeat instructions at various stages. This can be done by adding prompts that reiterate previous questions and ask the model to revisit its reasoning process. For example: “Can you revisit your explanation of how artificial intelligence is impacting society?” By repeating instructions, users can help LLMs maintain a balanced view of information.
Using delimiters within prompts is another way to enhance a large language model’s ability to process complex questions by providing visual cues that help it distinguish between different parts of the task. Delimiters are a sequence of characters or symbols that serve as important markers, enabling the LLM to recognize key places or distinct sections within your prompt. The use of specific delimiters such as curly brackets {}, double hash signs ##, and horizontal lines — can function effectively in this context. For instance, a possible prompt could be: “Summarize the text given between double hashtags ##text## and output it as a paragraph with no more than 50 words.” By incorporating these visual cues, you can help the LLM navigate complex tasks with greater ease and accuracy.
Employing a few-shot approach can leverage the model’s existing knowledge to generate more accurate outputs. The few-shot approach involves providing only a small set of relevant examples or context alongside the main prompt. For example: “Describe a character like Jack Dawson from James Cameron’s Titanic who embodies the spirit of youthful rebellion and nonconformity”
Meta prompts are prompts that create new prompts. With meta-prompts, we can hand over the task of crafting a prompt to the model itself. For instance: “Create a prompt that asks an LLM to explain how the concept of artificial intelligence is impacting modern society.”
Chain-of-thought prompting involves guiding the LLM through its thought process by asking it to explicitly justify and reason about its responses at various stages of the task. This can be achieved by adding questions such as “How would you approach solving a math problem like 2x2+5x−3=0? Please explain your steps.”
The reason-and-act technique takes this approach a step further, involving two distinct prompts: one for the LLM to provide a justification or explanation, and another for it to generate an output based on that justification. For example: “Explain why you think climate change is a pressing issue in today’s world. Based on your previous response, what actions do you recommend individuals take to mitigate their carbon footprint?”
In addition to these techniques, understanding the distinction between system prompts and user prompts can aid in crafting effective prompts. System prompts are used to set the stage for interaction by including instructions or guidelines on how to proceed with conversation, and they are always placed before user input. These prompts cannot be changed once set, providing a clear foundation for the conversation. In contrast, user prompts are the questions or queries asked by the user, which can sometimes be overridden by follow-up questions. The system prompt works in conjunction with the user prompt to generate a response, allowing the model to effectively understand and respond to the user’s query.
By combining these techniques, educators and practitioners can craft more effective prompts that generate high-quality outputs from large language models.
LLM Settings
Adjusting key settings like temperature, top_p values, and presence penalties on a large language model allows you to customize its output to suit your needs, from generating more coherent or diverse text to controlling the level of risk-taking in responses. By fine-tuning parameters such as maximum sequence length and stop sequences, you can ensure that generated text meets specific requirements, such as tone, style, or format constraints.
Temperature
To fine-tune the model’s performance, you can adjust the level of randomness in its response by controlling temperature. Lower temperatures yield more deterministic results, while higher temperatures encourage more diverse and creative outputs. A general guideline is to use a lower temperature for tasks that require factual and concise responses, such as fact-based question-answering (QA), and increase the temperature for creative tasks like poem generation.
Top P
Top P (or top_p) plays a key role in a technique known as nucleus sampling. This method aims to strike a balance between randomness and predictability in text generation. By adjusting top_p, you can influence the level of confidence in your model’s responses. A lower top_p value tends to produce more confident outputs, while a higher value yields more diverse results.
It’s generally recommended that you alter top_p on its own rather than making changes to both it and temperature simultaneously. This allows for more targeted fine-tuning of your model’s behavior.
Frequency Penalty
The frequency penalty applied by LLMs serves as a mechanism to discourage repetition of tokens in the model’s response. This penalty is directly proportional to how many times each token has already appeared in both the prompt and response, making it more likely for words with higher frequency penalties to be avoided. By incorporating this feature, the model reduces repetition of words in its output, resulting in a more varied and natural-sounding response.
Presence Penalty
The model applies a penalty on repeated tokens, but assigns the same penalty value regardless of frequency. This means that a token appearing twice is penalized equally to one appearing 10 times, which helps prevent repetition in responses. A general recommendation is to adjust either the frequency or presence penalty, but not both, as this approach can help strike a balance between preventing over-repetition and encouraging varied language use.
Max Length
Specifying a maximum token count allows you to control the number of tokens the model generates, which is essential for preventing long or irrelevant responses and helping manage costs effectively. By setting this limit, you can ensure that the model stays focused on providing accurate and relevant information, rather than generating unnecessary text that may not be useful for your purposes.
Stop Sequences
To control the model’s response, you can use a string that instructs it to stop generating tokens at a certain point. This allows for precise control over the length and structure of the generated text. For instance, if you want the model to generate lists with no more than 10 items, you can include this specific instruction in the input string. By doing so, you can effectively tailor the output to meet your requirements.
Contex Length
Language models have a fundamental limitation - the number of tokens (~130 tokens are equivalent to 100 words) they can process, often referred to as their context length. This limit affects not only the complexity of inputs but also memory and coherence. Consequently, using smaller context lengths can significantly impair tasks such as text summarization, making them less effective or even unusable in certain situations.
Model
Max. Input Sequence Length
Equivalent Pages (500 words/page)
GPT-3.5
4,096
6
GPT-4 (8k)
8,192
12
GPT-4 (32k)
32,768
49
Llama-2
4,096
6
Llama-3 (8k)
8,192
12
Gemma2 (8K)
8,192
12
Llama-3.1(128k)
131,072
192
Final Thoughts
You’ve now gained a better understanding of large language models (LLMs) and their capabilities. By leveraging vast amounts of data, LLMs can identify complex patterns and relationships within language, enabling them to produce output that’s contextually relevant. However, there are still challenges to overcome, such as ensuring accuracy and mitigating bias. Nevertheless, the impact of LLMs is significant. To unlock their full potential, it’s essential to craft effective prompts and fine-tune settings. As research continues to advance LLMs, you can expect even more functionality from them.
My interdisciplinary background has equipped me with the ability to apply innovative software engineering techniques to tackle complex problems in both chemical and life sciences.
After completing my undergraduate degree with a strong foundation in …
All large language models (LLMs) have two fundamental limitations: LLMs lack knowledge of events that occurred after their training date, a phenomenon …


 Dr. Lochana C. Menikarachchi
Dr. Lochana C. Menikarachchi
