Advances in large language models made it easier for us to write and edit text, helping us create better content with less effort.
However, relying solely on cloud-based services can be limiting due to internet connectivity issues, cost and data privacy concerns. Fortunately, local LLMs offer a solution by allowing you to run these powerful models directly on your own devices. In this blog post, we’ll explore the key concepts, features, and best practices surrounding local LLMs, helping you understand their capabilities and how to get started with them.
No Time? Listen to the Audio Deep Dive!
Contents
LLMs on Your Laptop? Yes, It’s Possible!
Many of you may have been introduced to large language models (LLMs) through ChatGPT, which has become synonymous with LLMs as one of the first to reach a wide audience. After OpenAI released an early demo on November 30, 2022, ChatGPT went viral on social media, leaving many users familiar only with this particular LLM. This narrow exposure may lead some to misjudge LLMs, assuming they are massive and cannot be run on commodity hardware such as a typical laptop. The reality is quite different: fast-forward a couple of years, and now we have smaller yet more powerful LLMs that can be easily deployed on your own laptop, even for free!
Cloud-based Vs. Local LLMs
The following table lists some selected well-known LLMs. The arena score, which is used by LMArena’s LLM leaderboard (https://lmarena.ai/?leaderboard) to rank models based on their overall performance, indicates that newer, smaller LLMs are outperforming their larger counterparts. Please note that the parameter counts and sizes listed in the table are approximate.
Model
No of Parameters
Approximate Size
Arena Score
Organization
GPT-4o
200 Billion
400 GB
1335
OpenAI
Gemini Pro 1.5
600 Billion
1200 GB
1299
Google (Alphabet)
Llama-3.1 405B
405 Billion
810 GB
1266
Facebook (Meta)
Llama-3.1 70B
70 Billion
140 GB
1248
Facebook (Meta)
Gemma2 SimPO 9B
9 Billion
18 GB
1216
Google (Alphabet)
Llama-3.1 8B
8 Billion
16 GB
1171
Facebook (Meta)
GPT-3.5 (Free)
175 Billion
350 GB
1106
OpenAI
When it comes to deciding between cloud-based and local LLMs, several factors come into play. You’ll need to consider cost-effectiveness, security and privacy concerns, ease of use, model size limitations, control over data usage, and flexibility.
Cloud-based LLMs offer a low upfront cost with recurrent subscription fees. However, they also come with the risk of cyber threats to your sensitive user data, which can be a significant concern for you and your organization. On the other hand, local LLMs provide greater peace of mind regarding security and privacy due to local data storage. This means you’ll have more control over how your data is used and protected. However, local models require more upfront investment in hardware and expertise for setup and maintenance, which can be a barrier for some users. Additionally, local models are limited by their smaller size due to hardware constraints. But they also offer flexibility without reliance on internet connectivity, which can be beneficial in certain situations.
Ultimately, the decision between cloud-based and local LLMs depends on balancing these trade-offs based on your organization’s specific needs and priorities. By carefully weighing the pros and cons of each option, you can choose the best solution for your unique requirements.
What Do You Need to Run LLMs Locally: Models, Software and Hardware
If you’re intrigued by the idea of running LLMs that surpass the capabilities of familiar ChatGPT 3.5 on your laptop, there are several key factors to consider. First and foremost, you’ll need access to an LLM model that meets your needs. While there are many options available, some popular choices include Llama3.1, Gemma2, and Qwen2.5. Once you’ve selected a suitable model, you’ll also need a piece of software called an LLM serving framework to run it on your laptop. Popular choices include Ollama, Msty, GPT4All, and Jan. However, it’s essential to ensure that your computer has sufficient memory and processing power to handle the demands of running an LLM. While it is technically possible to run an LLM using just the CPU, having an NVIDIA graphics card can significantly optimize performance, making the experience more efficient and smoother overall.
Quantization: The Key to Running LLMs Locally
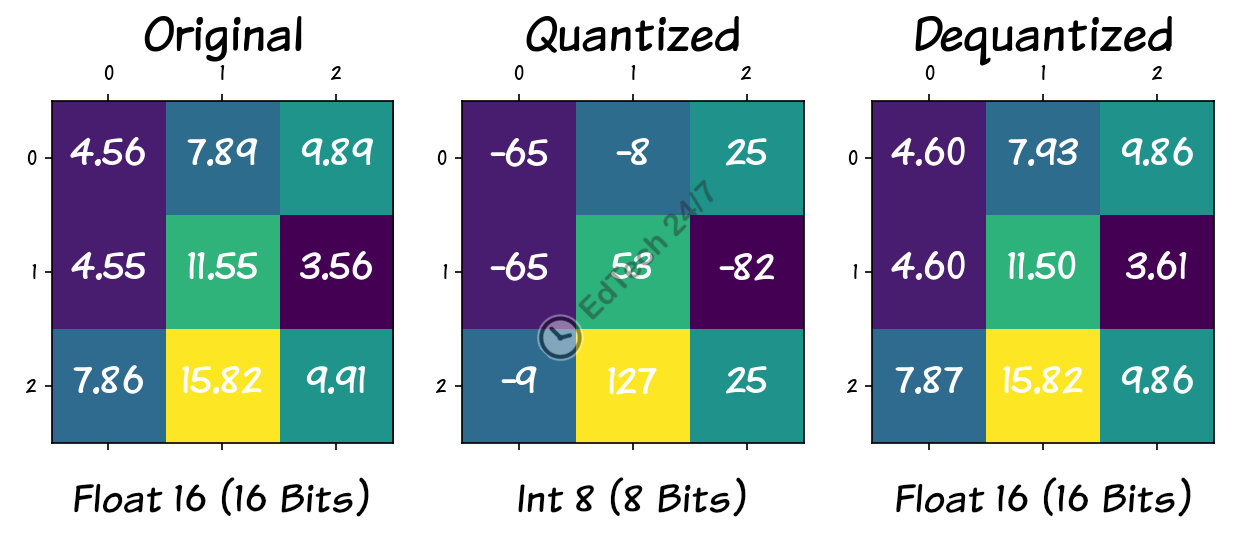
Quantization is a process used to reduce the size of a model by lowering the precision of its parameters, such as weights and biases. This is achieved by converting higher-precision representations to lower-precision ones while maintaining accuracy. For example, reducing 16-bit floating-point numbers to 8-bit integers can decrease both storage requirements (as smaller numbers require less space) and computation needs during inference time, making it possible to deploy large language models on devices with limited capabilities.
The actual conversion from higher to lower precision typically involves mapping the original values onto corresponding integer ranges. When converting 16-bit floating-point numbers into 8-bit integers, each 16 bits in a float can be represented by 8 bits or less in an integer. This process requires careful consideration of how values above and below certain thresholds are handled to avoid loss of information or biasing the model.
After quantization is complete, models must undergo dequantization during inference time. Dequantization involves reversing the effects of quantization by scaling back up from lower precision representations (like 8-bit integers) to higher precision values (such as 16-bit floats). This step ensures accuracy and reliability but requires additional computational resources.
The figure illustrates how 9 parameters are mapped into an 8-bit integer space, followed by a scaling process that restores them to 16-bit floats. Notably, during this transformation, parameters 4.56 and 4.55 undergo a change, resulting in their dequantized counterparts being rounded up to 4.60. Interestingly, all parameters except one (15.82) are affected in some way by this process. The question arises: how significant are these slight parameter changes on the overall performance of a model? While these changes can be negligible in most cases, they do impact the model’s performance, and their effect is influenced by the level of quantization applied.
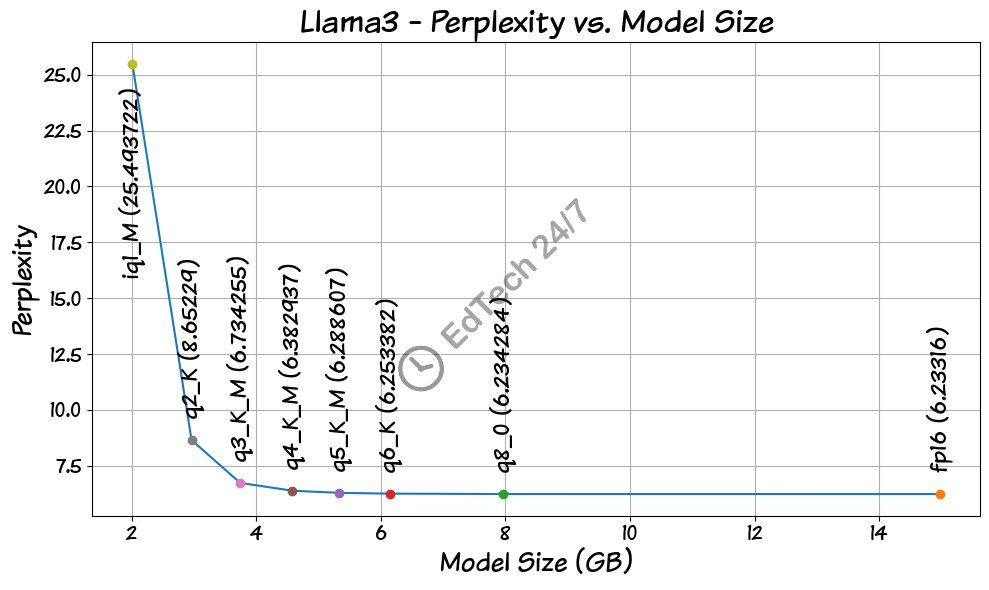
We can use perplexity as a metric to assess whether quantization affects text generation quality. Perplexity measures how well a language model predicts the next word in a sequence, with lower scores indicating better performance. This allows us to gauge the impact of quantization on the model’s ability to generate coherent and accurate text.
As you can see in the plot, the 8-bit quantized model (q8_0) has a perplexity almost identical to that of the full-precision model (fp16), suggesting it could serve as a drop-in replacement if we rely solely on perplexity for measuring model quality. Meanwhile, the 6-bit model (q6_K) exhibits a slightly higher perplexity than q8_0, implying it may be just as accurate as the original model. The clear advantage of quantization lies in its ability to accommodate an entire 7B-9B parameter model within GPU memory when configured for 8-bit or 6-bit operation, leading to substantial performance enhancements for local LLM models. Notably, perplexity appears to increase beyond the 4-bit model (q4_K_M), indicating that sticking to a 4-bit configuration or better is a wise decision.
What are LLM Benchmarks?
You’re likely to come across the term LLM benchmarks when evaluating LLMs. In essence, these benchmarks serve as standardized frameworks for assessing an LLM’s performance in various applications. They provide a way to measure how well a model can perform tasks such as text generation, summarization, and code completion. Using LLM benchmarks is essential when selecting a model because they enable you to compare the capabilities of different models across different domains. By leveraging these benchmarks, you can identify which models excel in specific areas and make informed decisions about which one best suits your needs.
Following are some of the most widely used LLM benchmarks, which have become essential tools for evaluating the performance of large language models.
MMLU: Measures a model’s ability to solve different tasks, containing 14,000 questions in 57 different topics, from math and anatomy to US history and law.
GPQA: A challenging graduate-level multiple-choice question set crafted by domain experts, including 198 questions. It is a super difficult version of MMLU.
ARC: Includes grade-school science questions that test a model’s ability to understand scientific concepts.
HellaSwag: A benchmark for common sense reasoning, where the model is provided with the beginning of a sentence and must choose between potential continuations.
TruthfulQA: This benchmark measures a model’s propensity to reproduce falsehoods found online.
Winogrande: A common sense reasoning benchmark that tests a model’s ability to understand everyday situations.
GSM8K: A benchmark containing grade school math word problems, making it great for measuring the ability to solve multi-step math reasoning problems.
HumanEval: A benchmark that measures functional correctness by generating code. It includes 164 Python programming problems that test a model’s ability to write correct and efficient code.
Benchmarks for LLMs can be run in two distinct modes: zero-shot and few-shot learning. In zero-shot learning, the LLM is prompted without any specific examples, relying solely on its general understanding of the task to generate accurate results. This approach leverages the model’s ability to generalize from broad concepts to new scenarios.
In contrast, few-shot learning presents the LLM with several concrete examples of task performance. By learning from these instances, the model can adapt more effectively to new scenarios and improve its overall accuracy.
Selecting the Right Model for Your Use Case
When it comes to selecting a local LLM, one-size-fits-all might not be the best solution. While there are many models that excel at a wide variety of tasks, a more tailored approach is necessary. One way to gauge how a model performs in a particular area is through LLM benchmarks, which we introduced earlier.
When selecting an LLM, I follow a multi-step approach. Typically, it starts with a web search to identify available options. Given my hardware constraints, I tend to opt for the largest model that I can run on my GPU’s memory. To further evaluate the candidates, I consult an LLM leaderboard like LMArena, which provides a general idea of each model’s performance relative to others in its class. Next, I examine LLM benchmarks to gain a more detailed understanding of how each model compares against its peers. Finally, I take the top contenders and test them with real-world problems that require specific solutions, allowing me to determine which model best meets my needs.
Obtaining LLM models is relatively straightforward, thanks to built-in mechanisms within LLM serving frameworks. In many cases, these frameworks default to 4-bit quantized models. If you prefer a more manual approach, you can download models from online repositories like Hugging Face (https://huggingface.co/). When selecting a model, choose an instruct-tuned model if your intention is to engage in conversation with the model. Instruct-tuned models are specifically designed to understand and respond to conversational input, making them ideal for chat applications. By contrast, base models primarily function as text completers.
Choosing the Right LLM Serving Framework
I’ve experimented with numerous local LLM serving frameworks over the past couple of years. While I don’t have an exact count, I estimate there are at least 50+ options available. Most of these frameworks are built on top of llamacpp, an open-source LLM serving framework (https://github.com/ggerganov/llama.cpp). The limitations in these frameworks often stem from the same constraints present in the version of llamacpp they’re based on. Some local LLM serving frameworks come as all-in-one desktop apps with user-friendly interfaces, making them accessible to a broader audience. Others employ a client-server model, where users interact with the framework through an application programming interface (API) or a command-line tool.
When choosing an LLM serving framework for your needs, you have several options to consider. Among the four frameworks mentioned in the blog post - GPT4All, Msty, Jan, and Ollama - three of them (except Ollama) fall under the desktop app category. If your primary use case involves chatting with the LLM in a way similar to interacting with free ChatGPT, a desktop app might be the most suitable choice for you.
However, if you wish to pair the LLM with a third-party UI or an editor of your preference, Ollama’s (https://ollama.com/) client-server model is a great option. All four frameworks are actively being developed, with new versions released on a weekly or monthly basis. As they frequently receive new features, a feature comparison may not be as useful as it would otherwise be.
For those starting out and using laptops equipped only with CPUs, GPT4All (https://www.nomic.ai/gpt4all) might be a good option to consider. Both Msty (https://msty.app/) and GPT4All offer retrieval-augmented generation (RAG) pipelines, making them powerful tools for searching and retrieving information from external knowledge sources. Jan also offers a nice interface but lacks RAG support. Additionally, both Msty and Jan advertise themselves as local-first, online ready frameworks. These frameworks allow interfacing with online LLMs such as ChatGPT, Gemini and Claude in addition to local LLMs. Ollama stands out as a great option for running LLMs headlessly, allowing you to pair it with third-party UIs or code editors like Visual Studio Code.
All four frameworks come in the form of single-file downloads and are easy to install by simply downloading and clicking on the installer. Desktop apps like Msty and Jan expose their functionality through an OpenAI-compatible API, making them accessible to third-party apps and editors. Additionally, all four frameworks have built-in mechanisms for searching and finding language models.
While all of these frameworks allow free personal use, some require commercial licenses for commercial use. For instance, Msty requires a commercial license for such purposes, highlighting the importance of taking a closer look at the licensing requirements of each framework before making a decision.
Essential Hardware Upgrades for Optimal Performance
You don’t necessarily need a powerful laptop with an NVIDIA GPU and lots of VRAM (Video Random Access Memory) to run LLMs, but having one is certainly advantageous. Technically, you can still run LLMs using just your CPU, but the experience will be much smoother and faster if you have a dedicated GPU on board. Even 4GB of VRAM can be useful, as some of the layers of the LLM can be offloaded to the GPU, freeing up resources for other tasks and improving overall performance. However, having at least 8GB or more of VRAM will allow you to run larger models in their entirety on the GPU, taking full advantage of its processing power and reducing reliance on your CPU.
As for laptops with dedicated NVIDIA GPUs, prices can vary depending on the amount of VRAM available. Laptops equipped with a 4GB NVIDIA GPU typically fall within the price range of 800−1,200 USD. In contrast, laptops featuring an 8GB or more NVIDIA GPU usually cost between 1,200−2,500 USD. For those looking for high-end options, laptops with 16GB or more NVIDIA GPUs can range from 2,000 to 4,000 USD or more.
Keep in mind that these are general price ranges and may vary depending on other factors such as the laptop’s processor speed, RAM capacity, display quality, and brand.
Final Thoughts
Now that you’ve explored the world of local LLMs, you know that leveraging them offers numerous benefits, including improved performance, reduced latency, and enhanced security. By downloading and installing a suitable framework, you can access a wide range of LLMs, each with its unique capabilities and strengths. With the right hardware upgrades, such as dedicated GPUs, you can unlock even more potential from these models. As you integrate local LLMs into your own projects, you’ll be able to create faster, more accurate, and personalized language tools.
My interdisciplinary background has equipped me with the ability to apply innovative software engineering techniques to tackle complex problems in both chemical and life sciences.
After completing my undergraduate degree with a strong foundation in …


 Dr. Lochana C. Menikarachchi
Dr. Lochana C. Menikarachchi
